こんにちは!BC チームでエンジニアをしている id:d-kimuson です。
最近、弊チームで構築した社内向け Web API のバックエンド設計をしたので事例として紹介しようと思います。
フレームワークとして NestJS を採用していますが、NestJS Way よりも TS Way を意識した設計をしており、このエントリの主題でもあるため、TS Backend の設計事例として読んでいただければと思います。
対象システムの概要
- 社内の他サービス向けの Web API で、他チームのサービスを経由してエンドユーザーに届く中間システム
- チーム内のサービスからもチーム外のサービスからも叩かれる想定
- チーム外からも叩かれるため、なんらかのスキーマを共有したいというモチベーションがある
- → 2023 年現在で標準的な OpenAPI Specification (以後 OAS と呼びます) を共有したい
- その他の採用している技術や環境
- Node.js v18
- ORM として Prisma
なぜ NestJS か?
システムの概要で触れたように、本システムでは OpenAPI のスキーマを吐き出したいというモチベーションがありました。
TypeScript における Server/Client 間でのスキーマの共通化としては tRPC や frourio 等も選択肢としてあります。
しかし、今回のシステムでは、クライアント側は TypeScript とは限らないため、言語に依存しない標準的なスキーマとして書き出す必要があり、OAS を採用しました。
OAS スキーマを用意するときは、実装とスキーマが一致することを保証するため
- コードファースト: 実装を書くと実装に沿ったスキーマが生成される
- スキーマファースト: (OpenAPI の)スキーマを書くと実装のボイラープレート(あるいはそのまま使える実装)が生成できる。また実装に対する制約の型定義等が生成され、スキーマを満たす実装しかかけない状態になる
の 2 つのいずれかの選択肢を取るのが望ましいと考えています。
今回は先にスキーマを用意したかったのでスキーマファーストのアプローチの方が望ましかったのですが、TS Backend においてスキーマファーストを適切に行うスタンダードな方法があまりなく、コードファーストなアプローチを採用しつつ、インタフェースだけ先にコーディングする形で「先にスキーマを用意したい」という要件を満たすことにしました。
コードファーストのやりやすさとして、NestJS はコントローラーの引数・戻り値の型がそのまま OAS が書き出され、体験がとても良いことに加えて
- チームでの採用事例があったこと
- (Express 等の薄いフレームワークと比べ) NestJS では包括的に Web 開発における機能をフレームワークとして提供してくれるため、Web 開発全般で必要な標準的な機能を再実装することなくドメインの API 開発に集中できること
等の利点もあることから、フレームワークとして NestJS を採用しました。
基本的な方針
公式ドキュメント・エコシステムの型チェックオプションとは距離を置く
NestJS 公式のジェネレータでボイラープレートを作成すると、TypeScript のデフォルトでは strict オプションによって off にされている
- any を許容するオプション
- null 安全性をなくするオプション
が有効にされた状態の tsconfig.json が作成されます。
公式ドキュメントでも
export class CreateCatDto { name: string age: number breed: string }
のようなコンストラクタでの初期化がされていない DTO(Data Transfer Object) を標準的に紹介しており、strictNullChecks が off であることが前提となっていることがわかります。
可能な限りフレームワークの Way や公式ドキュメントの内容に沿っておくことはとても重要ですが、少なくとも NestJS 周辺の型チェック周りの行儀はそれほど良くないので、適切な距離感で付き合っていくことが大事だと思います。
関数型プログラミングを軸とする
NestJS はオブジェクト志向をベースとした他言語でも適用できるフレームワーク・設計を TS の世界に持ってきたようなフレームワークです。*1
標準でコントローラー層やサービス層、組み込みの DI 解決に class を使ったサンプルを提示していたり、実際に DI 機能を提供している点から素直に実装をするとオブジェクト志向的な設計・実装になる引力が働きがちだと思っています。
しかし、個人的に柔軟なデータ構造の取り回しがしやすい構造的部分型の型システムを持つ TypeScript においては、データ構造とふるまい(メソッド)をセットで定義するオブジェクト志向的なやり方よりも、型駆動でドメインのデータ構造を宣言し、ふるまいを関数として分離する関数型的なアプローチのほうが相性が良いと考えています。
したがって、今回の Web API 開発においては関数型プログラミングのエッセンスを軸に設計を行いました。
関数型プログラミングとは言っても、大事にしているのは
- いわゆる「Entity」に定義されるメソッドとデータ構造は、型と関数としてしっかり分離しよう*2
- 副作用を分離しよう
- 関数はユニットテストが書きやすい小さい単位で作っていき、それらを組み合わせることでビジネスロジックを構成しよう
という側面に重きを置いています。
一方、TypeScript における関数型プログラミングとしては、fp-ts 等のライブラリが提供する
- 関数のカリー化 (
(arg1, arg2) => retを(arg1) => (arg2) => retにする) - 関数合成・パイプ (
f(g(arg))ではなくpipe(arg, g, f)的な書き方)
等の機能を使うこともできますが、こういった書き方・ライブラリとは距離を置いています。
これは
- 標準の TypeScript の書き心地とはかなりズレてしまうこと
- 追加の学習コストが発生すること
- 標準とのズレによるチームでのメンテナンス性の低下
というデメリットがあるためです。
関数型を軸としたバックエンド設計として、書籍 Domain Modeling Made Functional を参考にしています。知見が少ない関数型ベースの設計手法が語られていてとても参考になりました。
基本的なコンセプトは以上の 2 点です。
ここからはより具体的なアーキテクチャや方針について紹介していきます。
型チェックを厳格にする
「公式ドキュメント・エコシステムの型チェックオプションとは距離を置く」でも紹介したように、公式がデフォルトで提供する型チェックはかなり緩い状態になっています。
今回は、tsconfig/bases の strictest オプションをベースにしつつ、NestJS で利用できるようにオプションを一部上書き指定しています。 以下は実際に利用している TS 設定の一部です。
{ "extends": ["@tsconfig/strictest", "@tsconfig/node18"], "compilerOptions": { "module": "commonjs", "declaration": true, "removeComments": true, "emitDecoratorMetadata": true, "experimentalDecorators": true, "allowSyntheticDefaultImports": true, "sourceMap": true, "outDir": "./dist", "incremental": true, "skipLibCheck": true, "importsNotUsedAsValues": "remove" // decorator で使う・eslint でやるので } }
特に後から緩い型チェックを硬い型チェックへの移行していくのは大変になりますので、硬すぎるくらいのチェックを適用して運用に併せて緩くしていくくらいのスタンスをオススメします。
また、この記事では特に断りがない限り以上の型チェックオプションが適用された TS 5.0 を利用していることを前提とします。
strictNullChecks と DTO と constructor
NestJS ではリクエストパラメタ/ボディ、レスポンスボディの型定義には DTO を使います。
DTO とはデザインパターンの一種で、一般的にビジネスロジック(メソッド)が含まれないデータをいれる箱のことを指します。厳密な定義は置いておいて、NestJS の文脈においては
- コントローラーの引数(リクエストパラメタ・ボディ)、戻り値(レスポンスボディ)のインタフェースを宣言する class であり
- 引数に関して class-validator のデコレータを書くと勝手にバリデーションをしてくれてれる class であり *3
@nestjs/swaggerによって、引数・戻り値をプロパティの型定義から OAS に書き出してくれる class
といった意味合いを持っていて、インタフェース宣言に加えてバリデーションやOAS書き出しの責務を持つ特殊な class だと思ってもらえれば良いです。
strictNullChecks オプションが有効な状態では公式ドキュメントに提示されている DTO のサンプル
export class CreateCatDto { name: string age: number breed: string }
を使うと、constructor でプロパティを初期化していないため型エラーが発生します。
constructor をちゃんと書いてあげるのが理想的ですが、class-validator のデコレータと Parameter Properties の併用ができないので
export class CreateCatDto { @IsString() name: string @IsNumber() age: number @IsString() breed: string public constructor( name: string, age: number, breed: string ) { this.name = name this.age = age this.breed = breed } }
のような非常に冗長な記述になってしまいます。
弊チームでは Non-Null Assertion Operator を使って
class CreateCatDto { name!: string age!: number breed!: string }
のようにして型エラーを回避することにしています。
また、チームでは Dto の使い方に関して、2 つの規約を敷いています。
- ① Dto は abstract class で宣言すること
- ② Dto を controller, dto 以外のファイルから参照しないこと
① を敷いているのは コントローラーの戻り値は Dto のクラスインスタンスではなくプレーンオブジェクトを返すように統一する ことが目的です。
TypeScript では、Dto 型のクラスの戻り値が指定されているときに、実際にはクラスインスタンスではなくプレーンオブジェクトを返しても型エラーにならないという挙動になります。
import { plainToClass } from "class-transformer" class SomeController { // class が private なフィールドを持たないときに継承関係ではなくプロパティの構造で型チェックされる仕様を利用してプレーンオブジェクトを返すパターン createCatV1(): CreateCatDto { return { name: "nyash", age: 3, breed: "A", } } // CreateCatDto のインスタンスを作成してインスタンスか返すが、プロパティは Object.assign で割り当てるパターン createCatV2() { return Object.assign(new CreateCatDto(), { name: "nyash", age: 3, breed: "A", }) } // CreateCatDto のインスタンスを作成してインスタンスか返すが、プロパティは plainToClass で割り当てるパターン createCatV3() { return plainToClass(new CreateCatDto(), { name: "nyash", age: 3, breed: "A", }) } }
上記の createCatV1 ではプレーンオブジェクトを返し、createCatV2, createCatV3 ではクラスインスタンスを返していますがどちらも型チェックを通る正しいコードです。
これらがいずれも許容される混在する状態では
- テストで
toBeInstanceOfで判定できなかったり - コーディングする上でインスタンスなのか、プレーンオブジェクトなのかを意識する必要があり、認知負荷が増える
といった辛さが想定されるので、「プレーンオブジェクトを返すこと」に一貫性をもたせるために ① Dto は abstract class で宣言すること の規約を敷いています。
② Dto を controller, dto 以外のファイルから参照しないこと に関しては、Dto はあくまで「OAS を書き出したり class-validator を使えたりするために、インタフェースが欲しいだけだけどやむなく class を使う必要がある」というだけなので、必然性のあるコントローラー層以外からは使うのはやめましょうね、というものです。
DTO の class との向き合い方は今回の方針以外にもいくつか考えられる*4と思いますが、いずれにせよ型チェック上の抜け穴になりやすいのでコーディング規約やガイドライン等でスタンスを明確にしておくことが望ましいと思います。
ドメインモデルは class ではなく単一ファイル内に宣言する type と関数によって宣言される
よく class で表現される Entity は、一般的にデータと関連するメソッド群を持ちます。
class UserEntity { public constructor( public id: number, public firstName: string, public lastName: string, public birthDate: Date, public isAuthenticated: boolean, public createdAt: Date ) {} public get fullName(): string { return this.firstName + " " + this.lastName } }
以上のような Entity は型と関数に分離して以下のように宣言します。
/* Orm からマッピングされた型 */ type User = { id: number firstName: string lastName: string birthDate: Date isAuthenticated: boolean createdAt: Date } /** * すべてではありませんが、DB のレコードとドメインモデルが対応関係になることも多いと思います * そういうケースでは以下のような形を取っておくと便利です * * @example UserEntity<{ posts: Post[] }> -- リレーションを持つデータ構造のパターンだったり * @example UserEntity<{ tag: 'Validated' }> -- 同じデータ構造でバリデーション済み等のライフサイクルを表すタグを付加したり */ export type UserEntity< AdditionalFields extends Record<string, unknown> = {} > = User & { age: number } & Omit<AdditionalFields, keyof User>; export const buildUserEntity = <T extends User>(data: T): UserEntity<T> => { return { ...data, age: age(data.birthDate), } satisfies UserEntity as UserEntity<T> }; /** * @desc * - メソッドに該当する処理は `Pick<EntityType, 依存するプロパティの一覧>` を第一引数に取る関数 * - こうすることで必要なプロパティが明示されるのと、部分型(例: `Omit<UserEntity, 'age'>`)に対しても最低限のプロパティが揃っていれば呼べるようになる */ const fullName = (user: Pick<UserEntity, 'firstName' | 'lastName'>): string => user.firstName + ' ' + user.lastName
型と関数が分離されているので、ロジックを別ファイルに持っていくこともできますが、ドメインモデルと同じファイル内にかかれているほうが凝集で、読みやすいので同ファイル内に置いています。
データ型と関数が分離されていることで、class では冗長な記述が必要だった型を使った制約の表現がしやすくなります。
例えば「バリデーション通過済みのデータでのみユーザー作成のロジックを実行できる」を以下のように型で表現・制約をつけることができます。
type ValidatedUserEntity = UserEntity<{ tag: "VALIDATED" }> // service const validateUser = (user: UserEntity): ValidatedUserEntity => { // バリデーションを通過したデータにのみタグ 'VALIDATED' を付加する return { tag: "VALIDATED", ...user, } } const createUser = async (validatedUser: ValidatedUserEntity) => { // ... } declare const user: User const userEntity = buildUserEntity(user) // validateUser を通過していないデータでは呼び出せない createUser(userEntity) // Argument of type 'UserEntity<User>' is not assignable to parameter of type 'ValidatedUserEntity'. const validatedUser = validateUser(userEntity) createUser(validatedUser) // 型エラーなしで呼び出せる
他にも例えばバリデーションを通過して認証済みに絞られているデータであれば type AuthenticatedUser = UserEntity & { isAuthenticated: true } のように型を作って制約として利用することもできます。
このように同じ User ドメインモデルでも一連の手続きのタイミング毎で取りうるデータ構造は代わります。
それぞれのステップを区別した・厳格な型で表現できると、暗黙的にではなく型チェックで呼び出しの制約等を制御することができます。
class ではこの辺の取り回しがし辛いですが、型と関数に分離してあげることで柔軟に・型駆動でビジネスロジックを記述していきやすくなります。
メソッドに対応する関数も Pick<UserEntity, 'firstName' | 'lastName'> のように必要なプロパティだけ列挙することで、より制約の強い部分型(例えばAuthenticatedUser)でも最低限のプロパティだけ持っていれば呼び出すことができます。
副作用を分離する
関数型プログラミングで大事にされるエッセンスの 1 つとして副作用の分離があります。
副作用とはすなわち「関数の戻り値を返す以外の効果」のことで、わかりやすいところで HTTP 通信・DB の Read/Write・ロギング等があります。
副作用の特徴として
- 外部状態に依存するため、処理が安定しづらい
- 例えば正しく実装された関数が依存する DB や HTTP 通信先の状態に影響されて壊れたりする可能性がある
- 外部の状態に依存するためテスタビリティが低い
- 事前に依存状態を用意する必要があり、テストケースが関数の入力 → 出力ではなく、事前の DB 状態 → 関数の出力(あるいは事後の DB 状態)になり、テストケースが読みづらい傾向にある
- 上手く DB がセットアップされない・テストケース単位での DB 分離が壊れた等、対象のテストケースとは直接関係ないレイヤーの問題でテストがフレイキーになりやすい
- (DB の副作用について) 副作用がボトルネックになり、テストの実行時間が長くなる
- DB 接続がボトルネックになる
- 融和策としてインメモリ DB への差し替え等のアプローチもあるが、根本的な解決にはならず、また本番と異なる環境でテストを回すことになってしまう
- 依存する DB の状態がテストケースごとに分離されている必要があるため並列でのテスト実行がしづらくなる
- DB 接続がボトルネックになる
というつらい側面があります。
今回のアプリケーションでは全体のアーキテクチャはレイヤー構造を取っていて、レイヤーレベルで副作用を許容する層としない層を分離することで、つらい範囲を狭めています。
ただし、副作用の分離と言ってますが純粋関数型の言語でない TypeScript では厳密にすべての副作用を分離することは難しくコストも見合わないので考えておらず、特に影響の大きい「外部との HTTP 通信」や 「DB 接続」を副作用と考えて分離しています。
特に補足がない限り、この記事内で副作用と読んだときはこれらを指すものとします。*5
レイヤー構造と副作用
アプリケーションで採用しているレイヤー構造は以下の通りです
| 層 | 説明 | 副作用 |
|---|---|---|
| domain-object | 上のセクションで説明したドメインモデル(型とモデルに閉じた関数)が入る層(関心がドメインモデル) | なし |
| サービス層 | 複数のドメインモデルに跨るビジネスロジックを実装する層(関心がシステム) | なし |
| リポジトリ層 | HTTP 通信や DB 依存があるときにデータフェッチを行う層 | あり |
| ユースケース層 | サービス層・リポジトリ層・domain-object のロジックを組み合わせて意味のあるユースケースを実装する層です層 | なし |
| コントローラー層 | HTTP リクエストを受けてレスポンスを組み建てる層です | あり |
依存関係は以下のようになります。
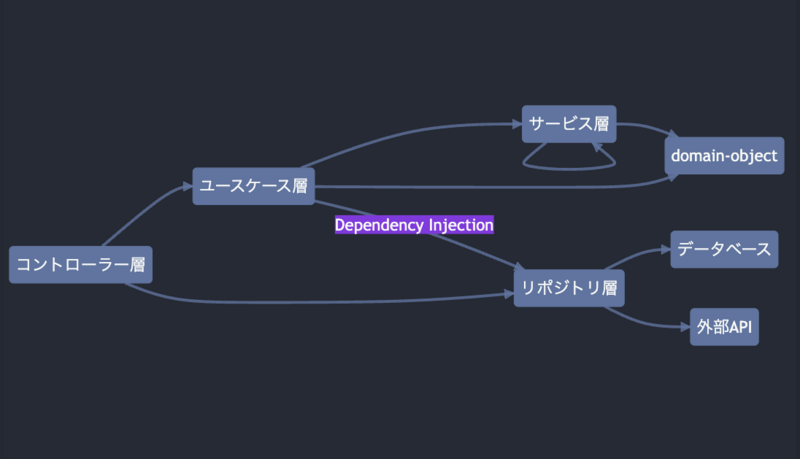
ユースケース層は厳密には副作用を持つ場合が多いですが、後述する Dependency Injection を使うことで、見かけ上副作用がない状態*6にしています。
jest.config レベルでテストを 2 種類の系統に分離する
副作用を分離したい 1 つの大きな理由として「テスタビリティを高めたい」という点がありました。 そこで、層ごとに副作用を扱うルールが分離されていることから jest.config レベルで副作用を持つ層のテストを副作用を持たない層のテストを分離しています。
以下は実際に使っている jest.config の抜粋です。
// jest.config.pure.ts import type { Config } from "jest"; import { baseConfig } from "./jest.config.base"; const config = { ...baseConfig, testMatch: [ "**/usecases/**/*.spec.ts", "**/services/**/*.spec.ts", "**/domain-object/**/*.spec.ts" ] } satisfies Config; export default config;
// jest.config.with-side-effects.ts import type { Config } from "jest"; import { baseConfig } from "./jest.config.base"; const config = { ...baseConfig, testMatch: [ "**/*.controller.spec.ts", "**/repositories/**/*.spec.ts" ], setupFilesAfterEnv: [ ...baseConfig.setupFilesAfterEnv, // DB 依存側はセットアップや DBリセット等の setup が必要になる "./src/test-utils/setup/separate-db-per-worker.ts", "./src/test-utils/setup/setup-prisma.ts", "./src/test-utils/setup/reset-table.ts", ] } satisfies Config; export default config;
あとは
{ "scripts": { "test:pure": "jest --config ./jest.config.pure.ts", "test:with-side-effects": "jest --config ./jest.config.with-side-effects.ts" } }
のような npm-scripts を用意しておくことで
$ pnpm test:pure # DB 非依存のテストのみ実行される $ pnpm test:with-side-effects # DB 依存のテストのみ実行される
のような形で分離して手元でテストを実行できます。
test:with-side-effects 側は
- ファイルごとに jest の worker 単位で並列化されていますが、ファイル単位では個別のテストケースが直列に動くこと
- テストケースのたびに DB のリセット処理が入ること
の 2 点が理由で、仮に DB の副作用がなかったとしてもテストケースごとにオーバーヘッドが発生する構成になっています。
test:pure が test:with-side-effects から分離されていることで、test:pure 側に不要なオーバーヘッドがかからず、軽量なテストとして手元で実行しやすくなり、TDD 的な開発がしやすくなると考えています。
test:pure 側ではインフラストラクチャへの関心がないビジネスロジック側に関心が置かれているため、このレイヤーを軽量に・高速にテストできるととても体験が良いです。
現時点での計測値としては、後者は 90 テストケースありフルテストで 82 秒程かかりますが、前者は 126 テストケースが 2.5 秒程で実行できます。
副作用のサンドイッチによる分離
基本的にサービス層・domain-object はあまり意識せずとも副作用のない関数になっていきやすいですが、ユースケース層は DB に依存することが多いので結構厳しいです。
副作用はできるだけ分離したいので

のようにリクエストの前後に副作用を集約できるような形式を取れるのであればこれが理想的です。
ただし、複雑なユースケースになってくると、DB から取得した値を元に他の値を DB から値を取得する必要がある場合や、処理の途中で副作用を挟まらずを得ないケースもあります。こういうケースではユースケース層から副作用を排除することは難しいため、Dependency Injection を使っていきます。
関数ベースの Dependency Injection
Dependency Injection と聞くとクラスベースの DI を思い浮かべる人が多いと思いますが、今回は高階関数を使った DI を使っていきます。
Injectable な関数を宣言するためのユーテリティ関数を用意します。
type ArgType<T extends Function> = T extends (...args: infer I) => any ? I : never; type InjectableFn = (...args: any) => (...args: any) => any; export type IInjectable< Deps extends Record<string, (...args: any) => any>, Args extends ReadonlyArray<unknown> = [], Ret = void > = (deps: Deps) => (...args: Args) => Ret; export const defineInjectable = < DepFns extends Record<string, InjectableFn>, Deps extends Record<string, (...args: any) => any> = { [K in keyof DepFns]: ReturnType<DepFns[K]>; } >( _depFns: DepFns ) => <Fn extends (deps: Deps) => (...args: any) => any>( fn: Fn ): Fn => fn satisfies IInjectable<Deps, ArgType<Fn>, ReturnType<Fn>>;
中身の説明は重要ではないので置いておきますが、高階関数を使って (ORM) => (引数) => Promise<取得した値> の形式で実装されたリポジトリ層の DI 解決をするユーティリティです。
以上のユーテリティを使って、ユースケース層は以下のように書きます。
// repository がこんな感じで定義されてるとして const findUserById = (prisma: PrismaClient) => async (id: number) => prisma.user.findUnique({ where: { id, }, }) // ユースケースはこう定義してあげます const loginUsecase = defineInjectable({ findUserById /* 依存するリポジトリ層, (prisma) => (arg) => Promise<Data> */, })( (deps /* DI が解決された (arg) => Promise<Data> を受け取る */) => async (id: number) => { const user = await deps.findUserById(id) // ... } )
コントローラー層からは、リポジトリ層に prismaClient (ORM Client) を Inject してあげてそのまま呼び出します。
const result1 = loginUsecase({ findUserById: findUserById(prismaClient), })(1)
テストからはリポジトリ層を実 DB 依存の元の関数からテスト用のものに差し替えてあげることで実 DB への依存をはがすことができます。
// テストでの呼び出し方 const result = loginUsecase({ findUserById: async () => ({ id: 1, firstName: "yamada", lastName: "taro", }), })(1)
高階関数での DI を使うことで副作用がない(取り除かれた)状態を作ることができました。 提示したサンプルコードは こちら で試すことができます。
例外戦略
TypeScript における例外は組み込みの throw がありますが
- 関数のインタフェースからどんな例外を投げるかわからない
- エラーハンドリングが漏れる可能性がある
というつらさがあり、代案として主に 2 種類の他のアプローチが提唱されています。
- 組み込みの例外を throw ではなく return すること
- サードパーティライブラリ等を使った Result 型を使うこと
- 正常系・異常系をラップした構造
result.isOk() ? result.value : result.errのようなインタフェースで正常系にアクセスさせる型
これらのアプローチではいずれも異常系が戻り値として関数のインタフェースに現れるので、関数を見れば異常系がわかること・異常系のハンドリングが漏れない点で throw のつらいポイントが解消されています。
throw は禁止すべきか?
throw は型安全なエラーハンドリング手法ではないので、特にビジネスロジックの濃い層ではできるだけ型安全な手法を取りたいです。
一方、throw に優れている点がないかというとそんなことはなくて 「コードがシンプルになる」 というとても大きなメリットがあります。
return Error や Result のみ(throw 禁止)でコードをちょっと書いてみるとわかるんですが、これはこれでとてもつらいです。React や Vue で props のバケツリレーつらいよね、みたいな話がありますが同種の辛さがあり、依存する関数から関数へひたすら Error (あるいは Result) をバケツリレーする必要が出てきます。
その点 throw だと一番下で投げた後、一番上のコントローラー層あるいはミドルウェアなりで catch して異常レスポンスを返せば良いので、ビジネスロジックを書いてる層のコードがとてもすっきりします。
このメリットは結構大きいと考えていて
- 型安全なエラーハンドリングをしたいケース(呼び出し元でハンドリングを期待するケース)
- そうでないケース
をしっかり定義して使い分けていく、というスタンスを取っています。
Result 型は使わず return Error する
Result 型は return Error と同じく
- インタフェースから想定される例外が読み取れる
- 利用側にハンドリングを強制させられる
というメリットを提供しますが、例外システムに標準でないライブラリを利用して強く依存することになるので、標準の機能だけで実現できる return Error 形式を採用しています。関数型のエッセンスは使うが、fp-ts を使わない理由と同様です。
return Error パターンを使う場合の注意点として、private なプロパティを持たない class は継承関係ではなくデータ構造で型チェックされてしまうため型チェック上の抜け穴が発生してしまう問題があります(参考)。
これを回避するために
const errorSymbol = Symbol() export abstract class BaseError extends Error { private readonly [errorSymbol]: undefined }
のような Base となるエラーを用意しておき、これを継承する形を取るのがオススメです。
throw と return Error の棲み分け
throw と return する例外の使わ分けについてですが、このプロジェクトでは例外を以下の 4 種類に分類しています。
SubNormalError- 準正常系な例外で、例えば「リポジトリ層でレコードなかった」とか「Unique 制約にひっかかった」とか「バリデーション通過できなかった」等の 仕様として想定される例外 を指す
AbnormalError- 無条件に 500 を返して良いもの
- 発生条件など想定されてはいるが、アプリケーションとして異常な状態で
- DB 接続が確認できない、依存する外部 API が動作していない等、発生条件は想定されているがアプリケーションとして異常な例外 を指す
UnExpectedError- その分岐を通ること自体が 開発時点で想定されない例外 を指す
- 網羅チェックや、型システム上は通る分岐だけど実際にはありえない場所等
HttpException- 投げると指定のレスポンスを返せる例外
そして
- AbnormalError と UnExpectedError はハンドリングを強要させるメリットが少なく、例外のバケツリレーのデメリットだけ受ける形になってしまうので throw する
- SubNormalError については呼び出し元でハンドリングを強制させたいので return する
- HttpException は Usecase/Controller からのみインスタンス化及び throw できる
という方針を取っています。 これで、型安全にハンドリングするメリットが薄い箇所のみ throw でコードベースをシンプルに保ちつつ、それ以外の場所で型安全に(ハンドリングを強要させた状態で)例外を扱うことができるようになりました。
その他 Tips
基本的なアーキテクチャ設計のコンセプトは以上になりますが、その他便利な Tips をいくつか紹介します。
eslint で参照ルールを設定する
コーディングルールを定めたらなるべく eslint で弾けるようにルールを設定しています。コードレビューで指摘が入るより効率が良いことと、強制力がより強いためです。
eslint-import-plugin の no-restricted-paths を使うとレイヤー構造の参照ルールを宣言できます。
弊社では
- DTO を Controller/Dto ファイル以外で使わない
- Usecase から別の Usecase を呼ばない
- Service から Repository を呼ばない
のルールを eslint で表現して設定しています。
.eslintrc.cjs
{ rules: { "import/no-restricted-paths": [ "error", { zones: [ { from: "./src/**/*.!(controller|dto).ts", target: "**/*.dto.ts", message: "Dto は Controller の引数・戻り値でのみ使用が許可されています", }, { from: "./src/**/usecases/*.!(spec).ts", target: "./src/modules/**/usecases/*.ts", message: "Usecase 層から別の Usecase 層の参照は許可されていません", }, { from: "./src/**/repositories/*.ts", target: "**/features/**/services/**/*", message: "Service 層から Repository 層への参照は許可されていません", }, ], }, ], } }
リテラル型とユニオン型はカスタム ApiDecorator を使う
NestJS の OAS 書き出しの機能は便利ですが、制約がいくつかあります。
- ① プロパティの型が type や interface だと書き出せない
- ② プロパティの型がユニオン型だと書き出せない
- ③ プロパティの型がリテラル型だと書き出せない
① についてはプロパティも Dto 使いましょうね、で良いんですが後者についてはデコレータを使って型定義を明示して上げる必要があります。
以下のようなユーテリティを用意しておくと便利です。
/** * @example ApiProperty({ * description: '説明', * ...enumSchema<Gender>(['male', 'female']) * }) */ export const enumSchema = <T extends string>( enums: readonly T[], example?: T ) => { return { example: example ?? enums[0], enum: enums as T[], } satisfies SchemaObject; }; /** * @example ApiProperty({ * description: '説明', * ...unionSchema([SomeDto, Some2Dto], exampleData) * }) */ export const unionSchema = < TargetDtoClass, const T extends ReadonlyArray<AbstractClass<TargetDtoClass>>, U = T[number] >( unions: T, example: U extends { prototype: unknown } ? U["prototype"] : never ) => { return { example, oneOf: unions.map((union) => ({ $ref: getSchemaPath(union), })), } satisfies SchemaObject; }; /** * @example ApiProperty({ * description: '説明', * ...arraySchema(enumSchema(...args)) * }) */ export const arraySchema = (itemSchema: SchemaObject) => ({ type: "array", items: itemSchema, });
ユニオン型やリテラル型(+これらを使った配列型)の場合には
type Gender = "male" | "female" class SomeDto { @ApiDecorator({ ...enumSchema<Gender>("male"), }) gender!: Gender @ApiDecorator({ ...unionSchema([SomeDto, SomeDto2], exampleData), }) someUnion!: SomeDto | SomeDto2 @ApiDecorator({ ...arraySchema(enumSchema<Gender>("male")), }) genders!: Gender[] }
のように宣言することで適切な OAS を吐き出すことができます。
実装後の課題感
まだ実装を進めているステータスですが、現時点での所感や振り返りをして行きます。
Usecase 呼び出しが Fat になりがちでつらい
主な副作用分離のパターンとして
- 副作用のサンドイッチ
- 副作用を DI するパターン
を想定していましたが、副作用分離を意識しないときの書き方と近くて書きやすかったこともあり、1 より 2 のパターンでの実装が多くなりがちでした。
2 のパターンでは依存する対象が多いと DI の呼び出し部分が Fat になりやすく
someUsecase({ repository1, repository2, repository3, // ... })(arg)
のような書き方になります。
冗長ではありますが、やむをえない部分ではあるので許容しています。ただし、DI が必要ないケースでまで DI していないかは注意していきたいなと思います。
また、関数型DIのライブラリである velona を使うとプレーンな高階関数ではなく、必要な時だけ inject することができるインタフェースになっています。
// リポジトリのサンプルの抜粋です import { basicFn } from './' const injectedFn = basicFn.inject({ add: (a, b) => a * b }) expect(injectedFn(2, 3, 4)).toBe(2 * 3 * 4) // pass expect(basicFn(2, 3, 4)).toBe((2 + 3) * 4) // pass
こういうアプローチであればテスト以外で依存する関数を用意しなくて良いので Usecase 層がFatにならないため、こういったアプローチを採用していれば良かったなと思っています。
外部 API に対するモックがつらい
レイヤー構造の紹介に載せた図ですが、この図を見てわかるようにコントローラー層からリポジトリ層の利用には DI を利用していません。これはコントローラー層では、実際のデータベースを使ったテストをしたかったことが理由です。
一方、こと外部 API に依存する処理に関しては実際にリクエストを送るのではなく、テストケースに応じた API レスポンスへ差し替える必要があります。DI を利用しない仕組みづくりをしてしまったので、差し替えるために Jest の mock が多用されており、辛い状態になってしまいました。
msw 等を使ってネットワークのレイヤーをモックをするような方針を取るか、コントローラー層からも DI ができる仕組みを整備すべきだったなという後悔があります。
VSCode で Go To Definition が使いにくい
関数での DI だとよくある話なのかもですが
const usecase = defineInjectable({ fetchUser, })((deps) => async () => { deps.fetchUser // <== こいつ })
の「fetchUser」の実装へ定義ジャンプをしたくて「Go To Definition」しても DI 対象を宣言している 2 行目にジャンプしてしまい、実装を読みにいけません。
依存性逆転されて実装ではなくインタフェースに依存しているので当然といえば当然ですが、実装開始して当初は少し困りました。
対策としては、インタフェースにジャンプすれば良いので「Go To Type Definition」でジャンプしてあげると実装に飛ぶことができます。
型と単体テストによるフィードバックが高速で体験が良い
テストを先に書いて実装を後から書いていく TDD の開発体験は、実際に Web API を呼び出して試すよりも実装があっているかのフィードバックが速い、という点でとても開発体験が良いです。
型も基本的にはテストと構造が同じだと思っていて
| チェック速度 | チェックできる範囲 | |
|---|---|---|
| 型チェック | とても速い | 型の範囲のチェック |
| DB 依存なしテスト | 速い | ロジックの検査 |
| DB 依存ありテスト | 遅い | DB の動き含めて包括的に |
のような特徴があります
柔軟な型を用いて関数の引数・戻り値の型を正確に・先に用意しやすいので、先にインタフェースやテストを用意しつつ、実装しながら型チェックと DB 非依存のテストで FB をもらえるのでとても体験が良かったです。
まとめ
NestJS における TS Backend 設計の一例と Tips を紹介しました。
TypeScript の型システムを活かしながら、型駆動・関数型プログラミングのエッセンスを軸に
- 型システム上抜け穴になりやすい NestJS のポイントを防ぐ方法
- 副作用をレイヤー構造で分離してテスタビリティ・開発体験を高められること
- 準正常系の例外を return し、異常系の例外を throw することで実装をシンプルに保ちつつ、例外を型安全に扱えること
等を紹介しました。
部分的にでも TS Backend 設計の参考になれば幸いです。
設計・執筆の参考にした文献
- Domain Modeling Made Functional: Tackle Software Complexity with Domain-Driven Design and F# by Scott Wlaschin
- TypeScript による GraphQL バックエンド開発 - Speaker Deck
- TypeScript の異常系表現のいい感じの落とし所 | DevelopersIO
- Documentation | NestJS - A progressive Node.js framework
- Introduction - Mock Service Worker Docs
- no-restricted-imports - ESLint - Pluggable JavaScript Linter
- Prisma で本物の DBMS を使って自動テストを書く - mizdra's blog
*1:あくまで筆者の個人的な解釈です。
*2:ここで言うEntityはO/R Mapper的な文脈ではなく、クリーンアーキテクチャにおける「ドメインモデルと紐づくビジネスルールがカプセルバされてるもの」という意味です。
*3:Pipe の設定は必要です。
*4:任意のprivateなプロパティを持つBaseEntityを継承させることで逆にクラスインスタンスに統一させるという選択肢も有ると思います。このやり方だとObject.assignやplainToClassが型安全性を損なうハッチになってしまうことが想定されるため弊チームでは避けています。しかしconstructorをちゃんと書くようにもすれば冗長性と引き換えに健全な形で運用できると思います。
*5:一般的にはロギング等も副作用に分類されます。
*6:副作用は引数からのコールバック関数に含まれていて関数の責務範囲には副作用がない・テストにおいて副作用がないことを指します。