こんにちはエンジニアのEadaedaです。
皆さんのチームではGitHub Actionsを使っていますか?ブロックチェーンチームではテストやリンター、デプロイといったワークフローをGitHub Actionsで行っています。
今まで、デプロイ以外のワークフローはGitHub-hosted runnerで実行、デプロイはSelf-hosted runnerで実行していましたが、運用していくうちに特定の環境内にあるサーバーで実行されるように仕組みを見直す必要がでてきました。このため全てのワークフローをSelf-hosted runnerに移行する対応を行いました。この記事では移行の際に見つけた便利なものや困ったことを紹介します。
Self-hosted runner
GitHub Actionsでは、基本的にGitHubが用意したVMでワークフローが実行されます。このVMをGitHub-hosted runnerと呼んでいるようです。別の方法として、自前で用意したサーバーで各ワークフローを実行することもできます。このときの自前で用意したサーバーをSelf-hosted runnerと呼んでいます。
サーバーは物理でも良いですし、クラウドに構築するのでも良いです。今回は先の「特定の環境内」という条件を満たすようにEC2を利用することとしました。つまり以下のようなシンプルな構成を考えていました。
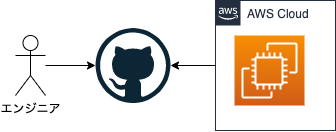
この構成はデプロイワークフローのために既に構築されているものと同じものでした。なので、各ワークフローをこのSelf-hosted runnerで動作するように書き直せば、一応移行は完了したことになります。
ただし、1つのRunnerにつき同時に実行できるジョブの数は1つですので、今の状態だとCI/CDワークフローをひとつずつ処理していくことになります。これではワークフローの完了待ちの時間が伸びてしまい、開発体験が最悪になってしまいます。
これを解決するパッと思いつくアイデアはSelf-hosted runnerのEC2インスタンスをたくさん用意することです。
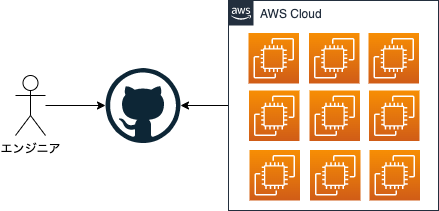
しかしこれはこれで問題があります。たくさんのEC2を手で起動するのは大変ですし、動きっぱなしのインスタンスの費用や、それぞれのインスタンスのメンテナンス工数などのコストがどんどん膨らんでしまいます。これらを解決するには、ワークフローの開始を検知して必要な数のインスタンスが起動、処理が終わったらインスタンスを終了する。というような仕組みにできれば良さそうですが、はたしてできるのでしょうか。
philips-labs/terraform-aws-github-runner でオートスケールするSelf-hosted runnerを整備する
できます。ピッタリのOSSがありました。
簡単に説明すると、ワークフローの開始を検知して必要な数のEC2インスタンスを起動、処理が終わりアイドル状態になったインスタンスはLambdaの定期実行により終了される仕組みを作ってくれるterraformモジュールです。READMEも充実しており良いなという印象です。
READMEに書いてあることなので、ここではセットアップについては説明はしませんが、快適にCI/CDを実行するためにREADME以外のこともやったのでいくつか紹介したいと思います。なお作業時点での最新バージョンはv1.2.0だったので、このあとの説明はv1.2.0での話であることをご了承ください。
terraform-aws-github-runnerモジュールの設定を考える
このモジュールは非常に多くの設定ができます。自分たちの使い方に合うような設定を考えてtfファイルに記述していきます。今回の構築でも色々考えて設定したのでいくつか紹介します。
AMIの準備
philips-labs/terraform-aws-github-runnerではSelf-hosted runnerの起動テンプレートで使うAMIを自分たちで用意することができます。CI/CDを実行するために事前に準備(例えばソフトウェアのインストールなど)できるものは準備をし、AMIにしておけばいくつかのstepを簡略化・高速化できます。CI/CDは速いと嬉しいので、できる準備はしておきたいです。
tfの記述
自分たちが用意したAMIを使うためにはami_filterのnameに使いたいAMIの名前を記述します。また、ami_ownersに利用しているAWSアカウントのIDを渡す必要があります。
今回はAMIのバージョニングを意識してhoge-YYYY-mm-ddという命名ルールにしたので、実際のami_filterの設定は以下のようになりました。(※hogeは例です。実際には意味のある単語を使っています)
ami_filter = { name = ["hoge-runner-*"] } ami_owners = [data.aws_caller_identity.current.account_id]
AMIの更新は、terraform applyをすることで行います。
docker pullしておく
プロダクトのCI/CDでは一部Dockerを使っています。例えばMySQLやRedisといったミドルウェアですね。これらはワークフローを実行するたびにdocker pullされます。イメージのサイズにもよりますが、そこそこ時間がかかってきます。
そこで、先にdocker pullしておいて毎回docker pullする必要が無いようにします。別な効果としてdocker pullのレートリミットに引っかかりにくくなるというものがあります。これに引っかかってしまうとCI/CDが停止してしまい非常に困るので回避できるのは嬉しいですね。
さて、やることはシンプルです。作業用のEC2インスタンスを起動、インスタンス内で以下のようにdocker pullします。
$ docker pull mysql:x.x.x $ docker pull redis:x.x.x ...
あとは作業用のインスタンスをもとにAMIを作って終わりです。
Self-hosted runnerの最大数を考える
同時に動作させられるSelf-hosted runnerの数の設定はrunners_maximum_countで設定できます。
// 最大5台 runners_maximum_count = 5
デフォルト値は3台となっていますが、プロダクトのワークフローは全部で10個以上あるので、確実に詰まります。なので適切な値を考える必要があります。雑に「えい」で決めてしまってもよいのですが、それよりはある程度証拠や説得力のある数値を計算した方が良いでしょう。かかるコストの計算や説明にも便利です。
そこで今回は過去の実績から計算することにしました。具体的には
過去一ヶ月、あるテスト系のワークフローが同時に実行されていた数 * テスト系ワークフローの数 + デプロイ系ワークフローの数
を計算します。実際の値は履歴をghコマンドで取得し、いもす法で計算します。
# gh apiでワークフローの履歴を取得する # 今回は5ページあったので 5.json まで繰り返す # YYYY-mm-ddは範囲の初日(≒一ヶ月前の日付) $ gh api "/repos/{HOGE_OWNER}/{HOGE_REPO}/actions/workflows/{HOGE_WORKFLOW_ID}/runs?created=>=YYYY-mm-dd&per_page=100&page=1" > 1.json # awkとかで雑にいもす法をやる。実装あってる…? $ jq -r '.workflow_runs[] | [.created_at, .updated_at]|@csv' *.json | \ tr -d \" |\ awk -F, '{imos[$1]++;imos[$2]--}END{for(k in imos)print k,imos[k]}' |\ sort |\ awk '{sum+=$2;print $1, sum}' |\ sort -k2n ... YYYY-mm-ddTHH:MM:SSZ 3 YYYY-mm-ddTHH:MM:SSZ 3 YYYY-mm-ddTHH:MM:SSZ 3 YYYY-mm-ddTHH:MM:SSZ 3 YYYY-mm-ddTHH:MM:SSZ 4 YYYY-mm-ddTHH:MM:SSZ 4 YYYY-mm-ddTHH:MM:SSZ 4 YYYY-mm-ddTHH:MM:SSZ 4
過去一ヶ月で同時に実行されていた数は4とのことでした。これを元にSelf-hosted runnerの最大数も設定し1ヶ月半ほど運用しましたが、CI/CDの詰まりなどは起きていないようなので、妥当だったのかなと考えています。
Self-hosted runnerの停止タイミングを考える
scale_down_schedule_expressionにcronの式を書くことで、スケールダウンを行うLambdaの実行間隔を指定できます。デフォルトは5分ごとですが、今回は1分ごととしました。理由としてはCI/CDを実行するインスタンスはできるだけ使い回されたくないなと考えたからです。
例えば、とあるブランチのワークフローが壊れており、それを実行したインスタンスも壊れてしまった場合、使い回されると他のブランチのワークフローも壊れてしまいます。これはあまり体験が良くないですよね。
その他にも、ビルド中に生成された中間ファイルなどが溜まって容量不足になるのを防ぎたい、もしくは中間ファイルによる影響をなくしたいというのもあります。もし使いまわしたい中間ファイルがあるなら、それはactions/cacheなどを使って明示的にした方が、ワークフローを読み解きやすくなるので良いでしょう。
まとめ
- 特定環境内で動作するGitHub Actionsを構築するためSelf-hosted runnerを利用することにした
- しかし、ワークフローが詰まらないようにするにはワークフローの数だけSelf-hosted runnerのサーバーが必要なため管理が大変だった
- そこで、philips-labs/terraform-aws-github-runnerを使ってオートスケールするSelf-hosted runnerの仕組みを構築した
- 運用に合わせて設定を考え、快適なCI/CDを構築する事ができた
今後の改善としては
- Dockerのレイヤーキャッシュまわりで躓き、オートスケールするSelf-hosted runnerにできなかったCI/CDへの対応
- CI/CDの詰まりがなかったか?を観測し、Self-hosted runnerの最大数やスケールダウンの実行間隔の再調整
- 管理できるメンバーを増やすようなドキュメントの整備やハンズオン
- Ephemeralオプションを試してみる
- Self-hosted runnerを1つのJobにのみ割り当てるオプション。使いまわしたくないのを確実にできる
philips-labs/terraform-aws-github-runnerではまだベータ機能だったので今回は使いませんでした
などを考えています。以上です。