駅メモ!チームエンジニアの id:yumlonne です。
この記事では Redis の sorted sets で実装していたランキング処理を MySQL に移行した仕組みを紹介します。
背景
駅メモ!には複数のランキングがあり、Redis の sorted sets を使うことでパフォーマンスの高いランキング処理を実現していました。 中にはリリースからの全期間に渡るデータを利用するランキングもあり、Redis のメモリ使用率は日に日に増えていく一方でした。 何度か Redis をスケールアップしてメモリを増やすことで対応していましたが、根本的に対応しなければ今後も Redis をスケールアップもしくはスケールアウトさせ続けるしか選択肢がなく、コストが増え続けてしまう状況でした。
調査したところ、一部のランキングがメモリ使用率の 2/3 程度を占めていることが判明しました。 そこで、その巨大なランキングを Redis から MySQL に移行させることを考えました。
Redis とデータベースの詳細
- Redis: Amazon ElastiCache Redis 7.x
- データベース: Amazon RDS Aurora v2 (MySQL 5.7 InnoDB)
ランキングについて
以下は対象となるランキングの要件と仕様です。
要件 1. 上位数件のユーザとそのスコアを取得できる
要件 2. ユーザは自分自身の順位を取得できる
要件 3. 順位は同率を考慮する(スコア 100,90,90,80 とある場合、順位は 1,2,2,4 となる)
要件 4. 上記の処理をそれぞれ 10ms 程度で実行できる
仕様 1. 古いデータを削除することはない
仕様 2. スコアの更新は増加のみで、減少させるような更新はない
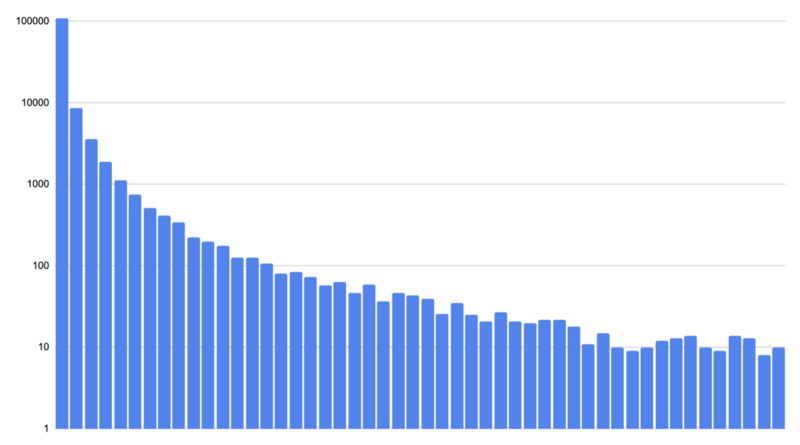
また、ランキングのスコアにはかなりの偏りがあります。 以下は偏りのイメージです。
縦軸はユーザ数ですが偏りが酷いので対数目盛にしています。
横軸はスコアです。イメージなので数値は表示していません。
MySQL でのランキング処理の課題
「要件 1. 上位数件のユーザとそのスコアを取得できる」 はスコアにインデックスを張っておけば 以下のように指定するだけで高速に取得できるため問題ありません。
SELECT * FROM ranking ORDER BY score DESC LIMIT 10;
問題は 「要件 2. ユーザは自分自身の順位を取得できる」 で、こちらはインデックスだけでは解決できません。ユーザの順位を求めるためには、そのユーザのスコアより高いスコアのユーザ数を知る必要があります。 下記 SQL にて自分よりスコアが高いユーザ数を取得できますが、スコアが低いユーザの場合、カウント対象行が多くなるためインデックスを有効活用しづらくなります。
SELECT COUNT(*) FROM ranking WHERE score > 50;
この問題を回避するためにカウント対象行を絞る対応を考えました。
ランキングを区切る
順位を出すときにカウント対象行が多くなりうる問題を解消するため、ランキングを区切ることを考えてみます。
例えば、事前に「1000 位のユーザーのスコアが 500」だと集計できているとします。 スコアが 450 のユーザーの順位は、「スコアが 450 より大きく 500 以下」を満たすレコード数に 1000 (位)を加えることで求められます。
| 順位 | スコア |
|---|---|
| 1000 | 500 |
| 2000 | 340 |
| 3000 | 250 |
| 4000 | 210 |
| ... | ... |
上の表のように順位を等間隔で区切ることにより、いかなる順位でもカウント対象をほぼ一定に保つことができ、パフォーマンスが安定します。 逆に、スコアを等間隔で区切るとランキングデータの偏りの影響でカウント対象がばらつくため不採用としました。
説明のため、以降はランキングを区切るデータのことをランキングインデックスと表記します。
サンプルスキーマ
CREATE TABLE `ranking` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `user_id` int(10) unsigned NOT NULL, `score` bigint(20) unsigned NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `user_uniq` (`user_id`), KEY `score_idx` (`score`) )
CREATE TABLE `ranking_index` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `rank` bigint(20) unsigned NOT NULL, `score` bigint(20) unsigned NOT NULL, PRIMARY KEY (`id`), KEY `rank_idx` (`rank`), KEY `score_idx` (`score`) )
順位取得処理のサンプルコード
順位取得処理のサンプルコードです。シンプルなコードなので Perl がわからない方でも流れを理解できると思います。
sub get_rank_by_score { # rankを算出するスコアを受け取る my ($score) = @_; # $scoreに近いranking_indexを探す my $ranking_index = get_ranking_index_by_score($score); if (defined $ranking_index) { if ($ranking_index->{score} == $score) { # ranking_indexのスコアがrankを求めたいスコアと同じだった場合はcountするまでもなく順位がわかる return $ranking_index->{rank}; } # ranking_indexのscoreと$scoreの間に存在するレコードをカウント my $cnt = exec_sql("SELECT COUNT(*) AS cnt FROM ranking WHERE $score < score AND score <= $ranking_index->{score}")->{cnt}; return $ranking_index->{rank} + $cnt; } else { # ランキング上位の場合はranking_indexが存在しない # この場合$scoreより高いスコアを持つレコードが少ないので素直にカウントする # 順位は1からスタートするので+1して返す my $cnt = exec_sql("SELECT COUNT(*) AS cnt FROM ranking WHERE $score < score")->{cnt}; return $cnt + 1; } } sub get_ranking_index_by_score { my ($score) = @_; # 与えられた$score以上のscoreのうち最も$scoreに近いレコードを取得する return exec_sql("SELECT * FROM ranking_index WHERE score >= $score ORDER BY score ASC LIMIT 1"); } sub exec_sql { # SQLを受けとって実行結果を返す # サンプルコードをシンプルにする便宜上の関数 # 本来はSQLインジェクション対策をすべきだが単純化のため省略 }
ランキングインデックスの管理
ランキングを区切ることによって順位計算時のカウント対象を減らし、パフォーマンスを向上させることができます。 しかし、ランキングを区切ったことで新たにランキングインデックスを管理する必要が出てきます。これを適切に更新しなければ、ユーザに誤った順位を返してしまうことになります。
更新
ランキングインデックスは以下の条件に当てはまるものを更新する必要があります。
更新前スコア(新規作成の場合は0) <= ランキングインデックスのスコア < 更新後スコア
例えば以下のようなランキングインデックスがあったとします。
| 順位 | スコア |
|---|---|
| 1000 | 500 |
| 2000 | 340 |
| 3000 | 250 |
| 4000 | 210 |
| ... | ... |
とあるユーザのスコアを 250 から 500 に更新する場合、ランキングインデックスは以下のように更新します。
| 順位 | スコア | 備考 |
|---|---|---|
| 1000 | 500 | 同率順位のデータが増えただけなので影響しない |
| 2000 + 1 | 340 | スコアが 340 を超えるレコードが増えたので順位が下がる |
| 3000 + 1 | 250 | スコアが 250 を超えるレコードが増えたので順位が下がる |
| 4000 | 210 | スコア 210 より上のデータが動いただけなので影響しない |
| ... | ... |
順位を +1 するのがポイントです。
スコアは更新しないので他のトランザクションの更新対象に影響を与えず、順位は 順位 = 順位 + 1 のようにすれば更新前の状態でロックを取っておく必要はありません。
これによりランキングインデックスのロック時間を最小限に抑えることができるようになります。
順位取得処理のサンプルコード
sub update_score { # 更新するユーザとそのスコアを受け取る my ($user_id, $score) = @_; with_transaction(sub { my $user_ranking = exec_sql("SELECT * FROM ranking WHERE user_id = $user_id FOR UPDATE"); my $before_score; if (defined $user_ranking) { # すでにuser_idに対応するrankingレコードがある場合は更新 # 更新前スコアを保持しておき、ranking_indexの更新範囲決定に使う exec_sql("UPDATE ranking SET score = $score WHERE id = $user_ranking->{id}"); $before_score = $user_ranking->{score}; } else { # rankingレコードがない場合はレコードを作る # 更新前スコアは0とすることで$score未満の全てのranking_indexを更新対象にする exec_sql("INSERT INTO ranking(user_id, score) VALUES ($user_id, $score)"); $before_score = 0; } # スコアの更新幅に含まれるranking_indexを更新する increase_ranking_index($before_score, $score); }); return; } sub increase_ranking_index { my ($before_score, $after_score) = @_; exec_sql("UPDATE ranking_index SET rank = rank + 1 WHERE $before_score <= score AND score < $after_score"); return; } sub exec_sql { # SQLを受けとって実行結果を返す # サンプルコードをシンプルにする便宜上の関数 # 本来はSQLインジェクション対策をすべきだが単純化のため省略 } sub with_transaction { # 与えられたコードブロックをDBのトランザクション内で実行する関数 }
定期実行処理
ランキング更新によってランキングインデックスの順位がずれていってしまうため、間隔が一定に保てなくなり、徐々にパフォーマンスが劣化していってしまいます。 これを防ぐため、ランキングインデックスが順位で等間隔になるよう定期的に調整する必要があります。
上記のランキング更新の都合で、ランキングインデックスのスコアは更新できないため、新しいランキングインデックスを挿入し古いランキングインデックスを削除する実装にしました。 これによりランキングの更新や順位取得に影響を与えずにランキングインデックスの間隔調整ができます。
駅メモ!ではランキングインデックスの間隔調整処理を毎日実行しています。ランキングの更新頻度やスコア分布などの特性によってパフォーマンス劣化のスピードは変わるため、適切な頻度を見極めて実行する必要があります。
テーブルのメンテナンス
定期実行スクリプトではレコードの作成と削除をしているため、ランキングインデックステーブルが断片化してしまいます。 サービスのメンテナンス時にランキングインデックステーブルに対して OPTIMIZE TABLE を実行することで対応しています。
まとめ
Redis の sorted sets で実装していたランキングを MySQL に移行するため、データベースでランキング処理をするようにしてみました。 その結果、Redis のメモリ使用量を元の 1/3 程度まで減らすことができ、Amazon ElastiCache Redis のスペックを下げることができました!
Redis 内で大きくなり続けるランキングにお困りの際はデータベースに処理を移すことを検討してみてはいかがでしょうか。